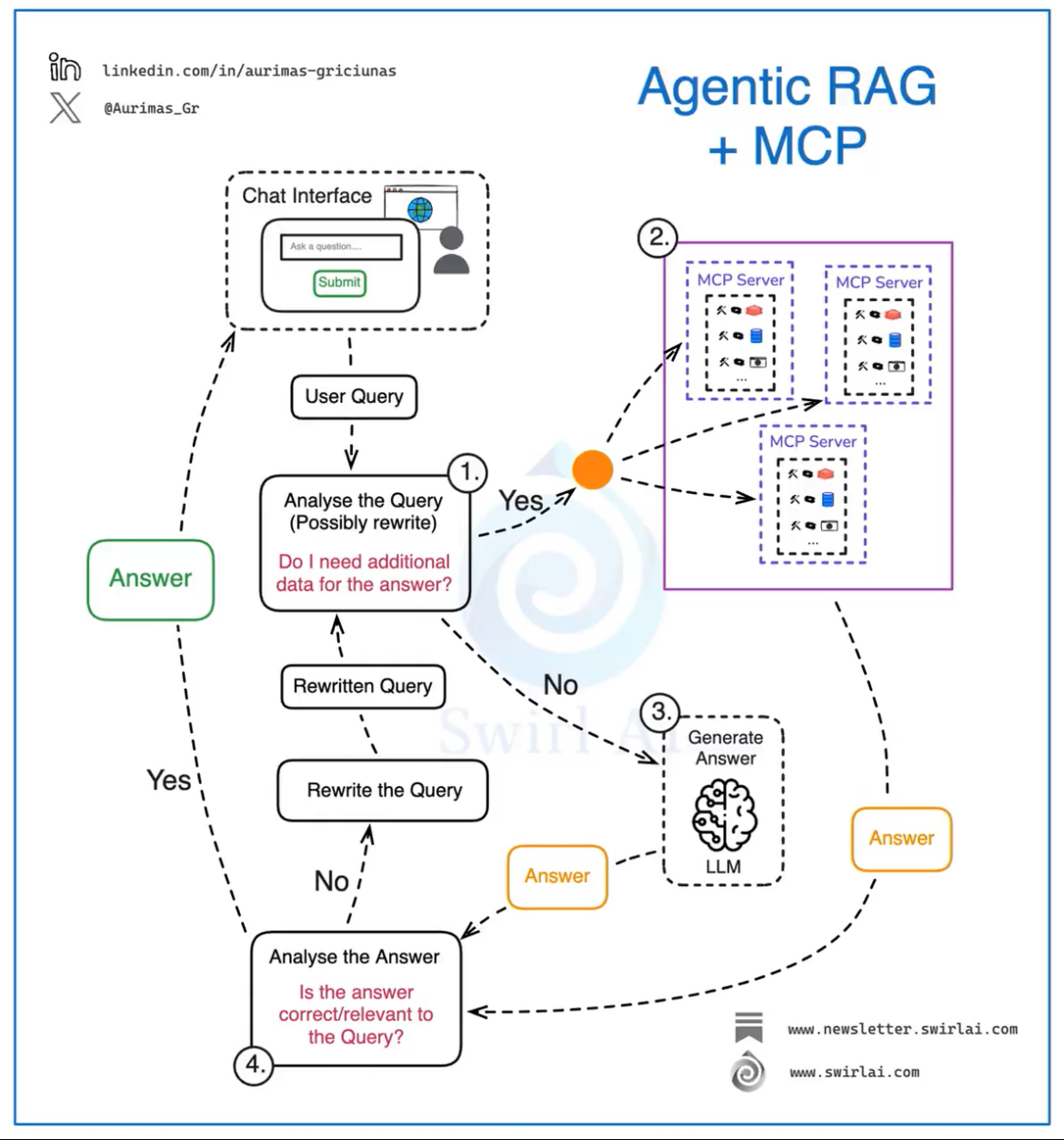
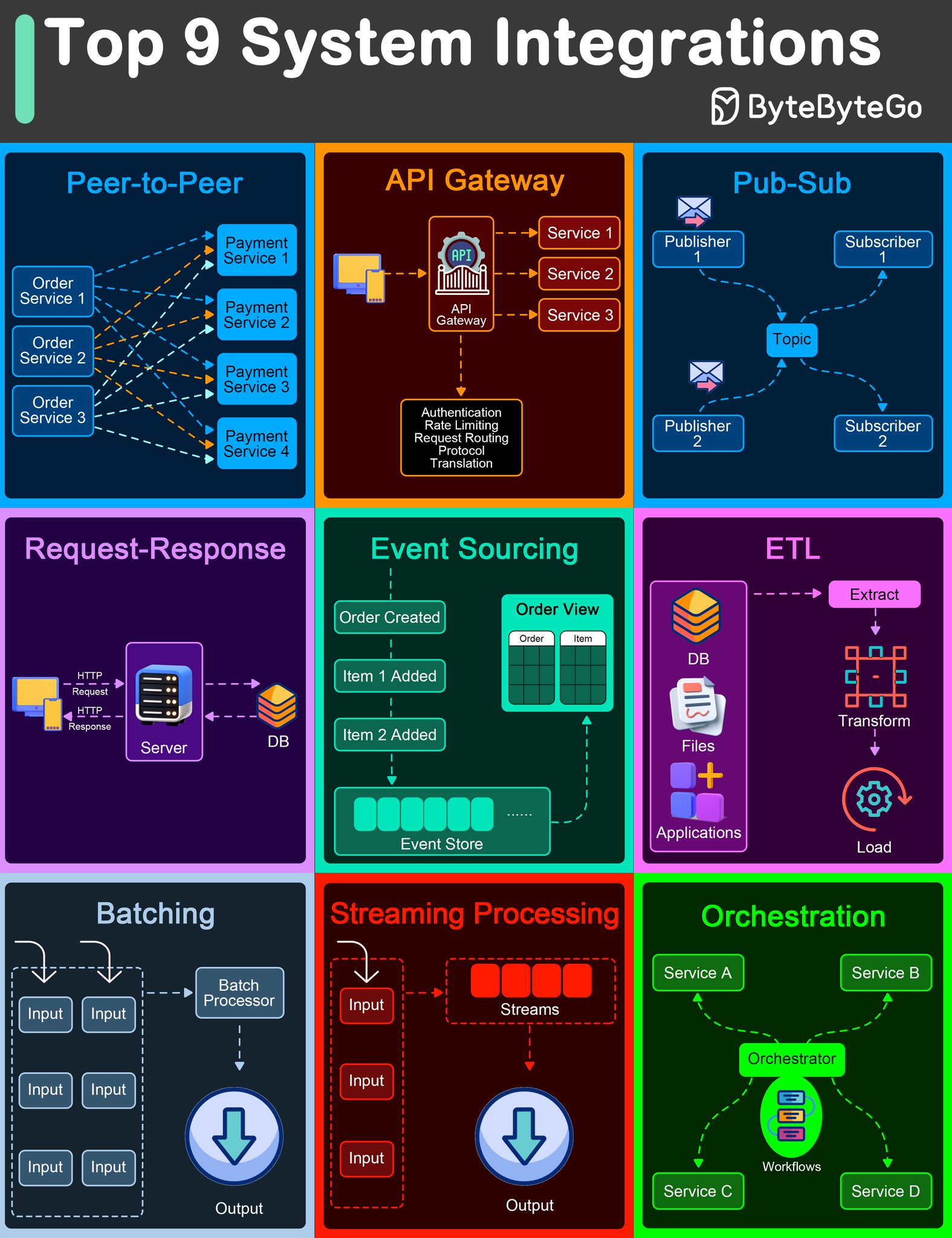
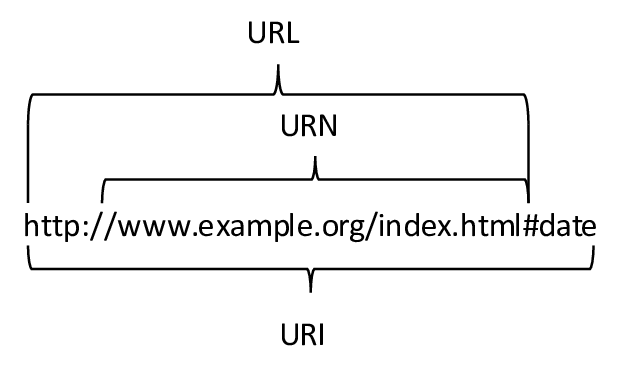
https://0x1.pt/2025/04/06/the-insanity-of-being-a-software-engineer/The Insanity of Being a Software EngineerIs something I think about often because I can’t help but wonder if most other jobs are like this.0x1.pt읽다보니 공감되서 따로 정리소프트웨어 엔지니어의 광기: 끝없는 기술 습득의 미로오늘날 소프트웨어 엔지니어로 살아간다는 것은 마치 끝없이 움직이는 타겟을 쫓는 것과 같다. 한 발자국 내딛을 때마다 목표 지점이 두 발자국 더 멀어지는 듯한 이 현실은 많은 개발자들에게 공감을 불러일으킨다. 과연 다른 직업들도 이렇게 숨 가쁜 것일까? ..