인공지능이 다음 단어를 예측하는 법
요즘 인공지능(AI)이 쓴 글을 읽으면 깜짝 놀랄 때가 많다. 챗봇과 가상 비서가 자연스럽게 대화를 나누고, 기사나 소설을 써 내려가며, 심지어 코드를 작성하기도 한다. 그중에서도 GPT-4와 같은 대형 언어 모델(LLM, Large Language Model)은 사람과 비슷한 문장을 생성하는 놀라운 능력을 가지고 있다. 하지만 이들은 도대체 어떻게 작동하는 걸까?
이 질문에 답하기 위해선 먼저 조건부 확률(Conditional Probability) 이라는 개념을 이해할 필요가 있다.
조건부 확률이란?
조건부 확률은 특정한 조건이 주어졌을 때 어떤 사건이 발생할 확률을 의미한다. 예를 들어보자.
한 집단에 14명의 사람이 있다고 가정해보자.
• 일부는 테니스를 🎾
• 일부는 축구를 좋아한다. ⚽️
• 몇몇은 테니스와 축구를 둘 다 좋아한다. 🎾 ⚽️
• 그리고 어떤 사람들은 둘 다 좋아하지 않는다.
이제 만약 우리가 무작위로 한 사람을 골라 “이 사람은 축구를 좋아할 확률이 얼마나 될까?“라는 질문을 한다면, 그 답은 단순한 확률 문제다.
하지만 만약 “이 사람이 테니스를 좋아한다고 이미 알고 있다면, 이 사람이 축구도 좋아할 확률은?“이라는 질문을 던지면, 이때부터는 조건부 확률의 영역으로 넘어간다.
이를 수식으로 표현하면 다음과 같다.
P(A | B) = 사건 B가 발생했을 때 사건 A가 발생할 확률
예를 들어, “오늘 비가 올 확률”을 예측한다고 해보자. 단순한 확률로 계산할 수도 있지만, 날씨가 흐린 날이라면? 흐린 날엔 비가 올 확률이 더 높아지므로, “흐린 날씨가 주어졌을 때 비가 올 확률” 즉, P(비 | 흐림) 이 더 높은 값을 가질 가능성이 크다.

이제, 이 개념이 어떻게 인공지능과 연결될까?
LLM과 조건부 확률: 다음 단어를 예측하는 원리
GPT-4와 같은 대형 언어 모델은 단순히 랜덤하게 문장을 만들어내는 것이 아니다. 사실, 이 모델들은 조건부 확률을 기반으로 다음 단어를 예측하는 확률 기계라고 볼 수 있다.
예를 들어, 우리가 다음과 같은 문장을 입력한다고 가정하자.
“나는 오늘 아침에 커피를 마셨다.”
여기서 모델의 역할은 이 문장 다음에 올 단어를 예측하는 것이다. 예를 들어, “그리고”라는 단어가 나올 확률과 “하지만”이 나올 확률을 비교할 수 있다.
이때 모델은 이전 문맥을 고려하여 가장 높은 확률을 가진 단어를 선택해야 한다. 즉, 다음 단어가 등장할 확률을 조건부 확률로 계산하는 것이다.
P(다음 단어 | 이전 단어들)
만약 우리가 “나는 오늘 아침에 커피를 마셨다.” 라고 입력했다면,
• “그리고”가 올 확률이 40%
• “하지만”이 올 확률이 20%
• “왜냐하면”이 올 확률이 10%
이런 식으로 확률 분포가 형성된다.
모델은 이 확률값을 비교해 가장 적절한 단어를 선택하며, 이를 반복하여 문장을 만들어 나간다.
LLM의 학습 과정: 고차원 확률 분포를 학습하다
그렇다면 이런 확률 값은 어떻게 계산될까? 바로 훈련(training) 을 통해 학습된다.
GPT-4 같은 모델은 방대한 양의 텍스트 데이터를 읽고, 각 단어와 문장 패턴을 학습한다. 이를 통해 단어들이 함께 등장하는 경향성을 파악하고, 단어 시퀀스에 대한 고차원 확률 분포(high-dimensional probability distribution) 를 형성한다.
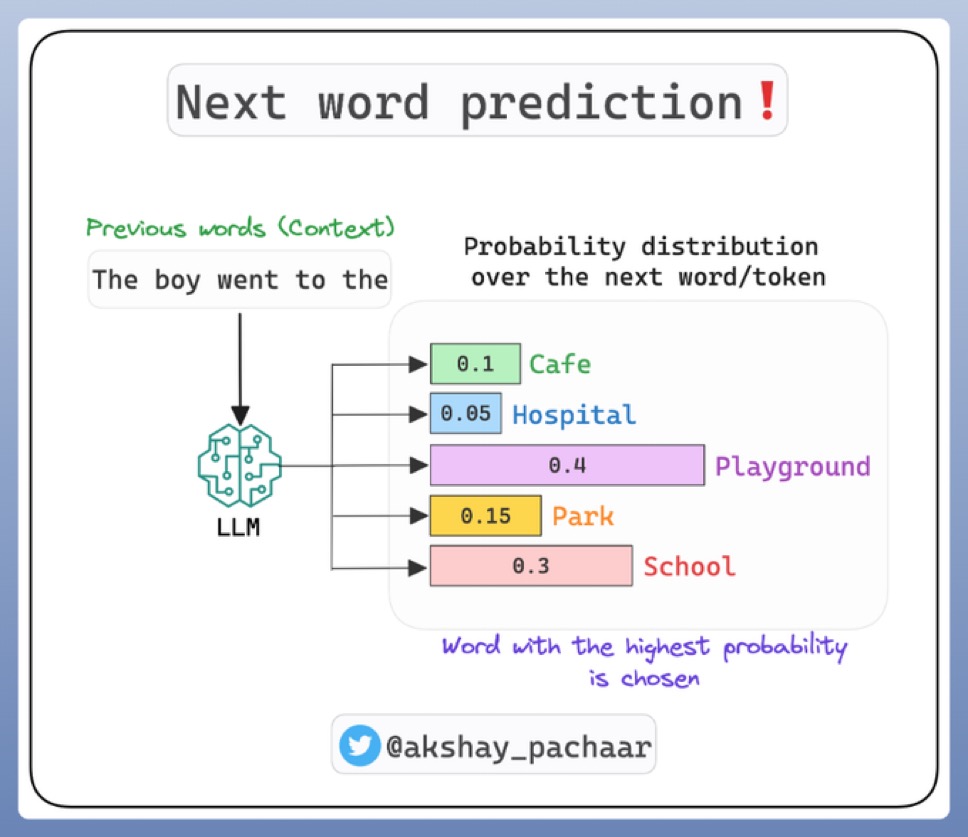
즉, “커피를 마셨다” 다음에는 “그리고”, “왜냐하면”, “그 후에” 같은 단어가 나올 확률이 높다는 것을 학습하는 것이다.
이 확률 분포를 조정하는 역할을 하는 것이 바로 훈련된 가중치(training weights) 이며, 이는 수십억 개의 매개변수(parameter)로 구성된다.
훈련 과정은 지도 학습(supervised learning) 방식으로 이루어진다. 방대한 데이터에서 정답(다음 단어)을 제공하며, 이를 맞히는 방식으로 모델을 최적화하는 것이다.
하지만 여기엔 또 다른 문제가 있다.
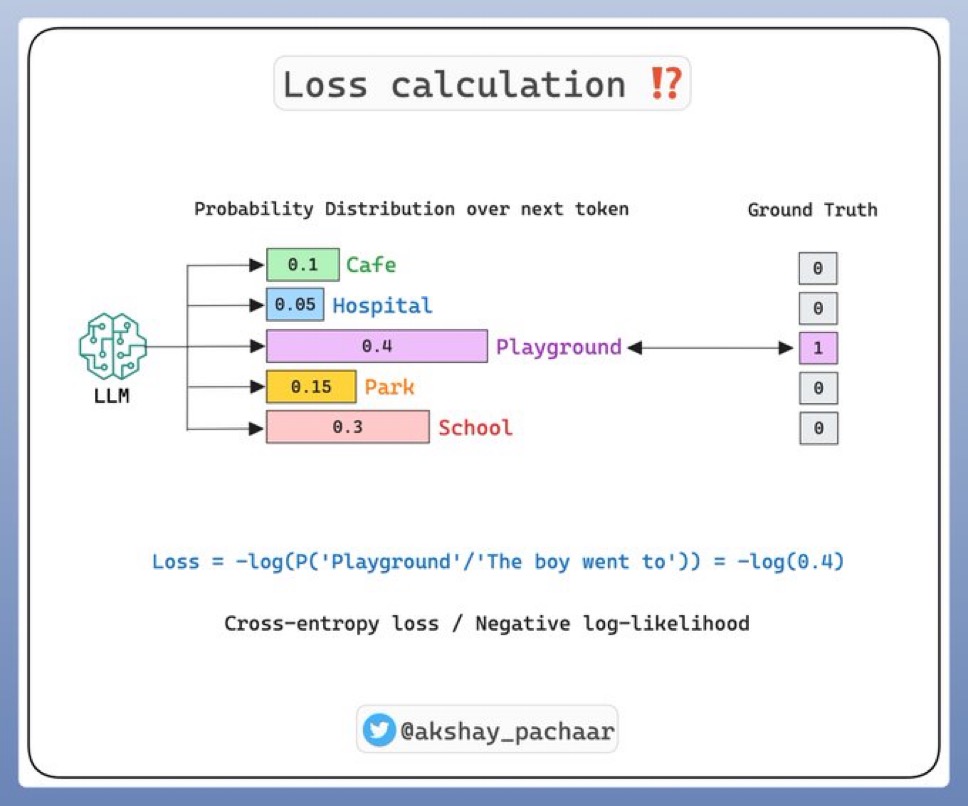
반복적인 패턴을 피하기 위한 “온도(temperature)” 개념
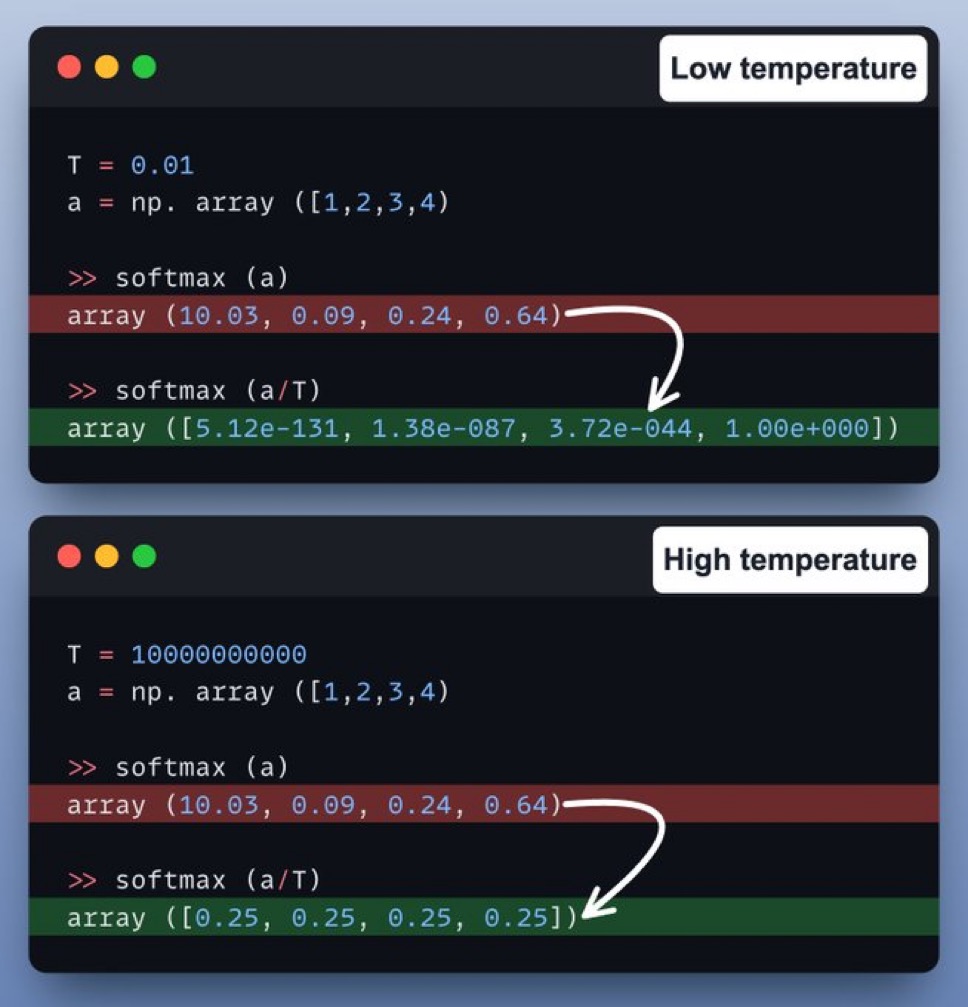
만약 모델이 항상 가장 높은 확률을 가진 단어만 선택한다면 어떻게 될까?
그렇게 되면 모델이 지나치게 반복적인 문장을 생성하거나, 너무 단조로운 문체로 글을 쓰게 된다. 이런 문제를 해결하기 위해 도입된 것이 바로 temperature 조절 이다.
temperature란 모델이 단어를 선택할 때 얼마나 무작위성을 허용할 것인가를 결정하는 값이다.
1. 낮은 temperature(0.2~0.5)
• 확률이 가장 높은 단어 위주로 선택
• 문장이 논리적이고 예측 가능한 흐름을 가짐
• 하지만 창의성이 떨어지고, 반복적인 표현이 나올 수 있음
2. 높은 temperature(0.8~1.2)
• 확률이 낮은 단어도 어느 정도 선택될 가능성이 있음
• 창의적인 문장이 나올 가능성이 높음
• 하지만 너무 높은 경우 문장이 의미 없이 흐트러질 수 있음

이 원리를 적용하면 모델은 항상 같은 문장을 반복하지 않고, 어느 정도 창의성을 갖춘 문장을 생성할 수 있다.
temperature는 다음과 같은 방식으로 확률값에 영향을 준다.
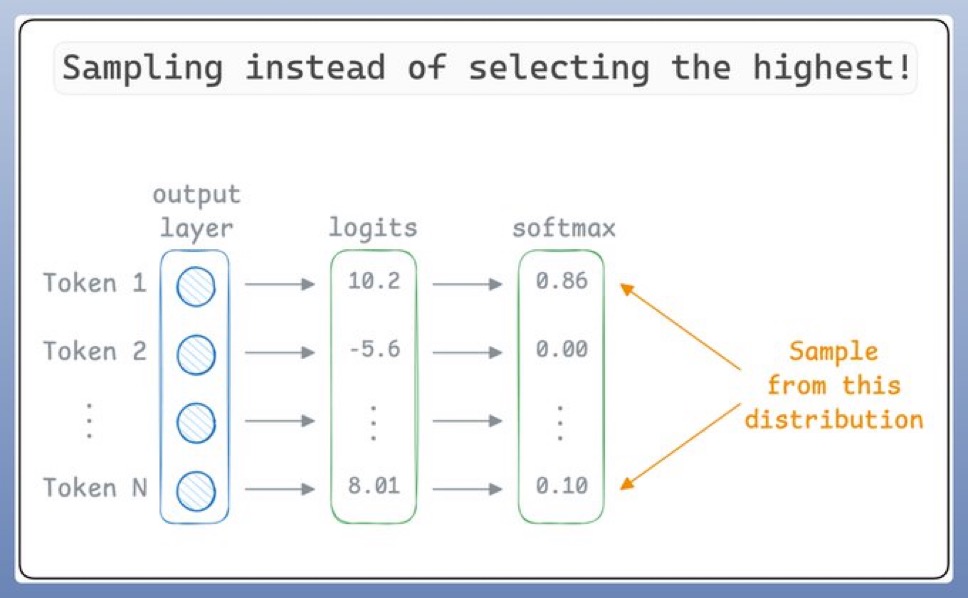
소프트맥스 함수(Softmax function) 를 사용해 확률 분포를 조절
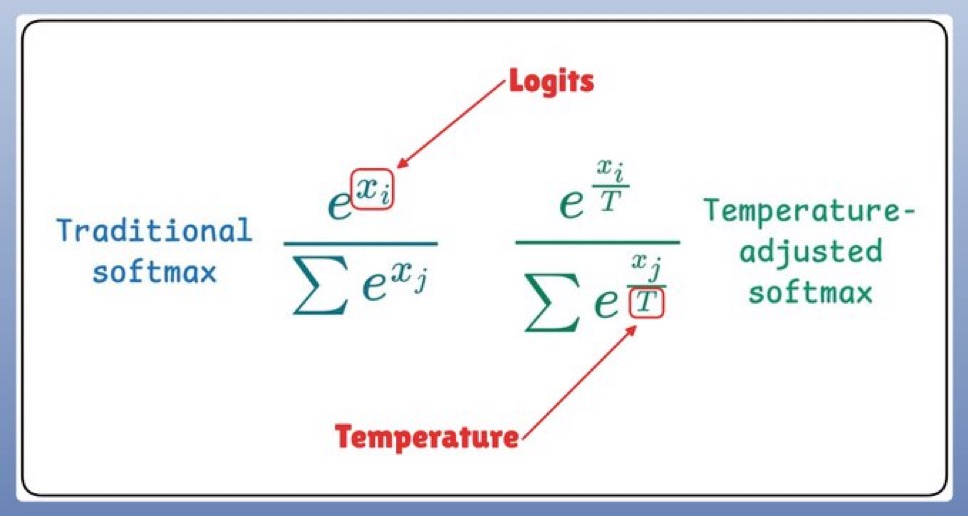
이 함수는 온도 값을 반영하여 확률을 재분배하며, 결과적으로 모델이 더욱 자연스럽고 유연한 문장을 생성하도록 만든다.
마무리: 언어 모델은 확률적 사고를 한다
GPT-4 같은 대형 언어 모델은 복잡한 알고리즘처럼 보이지만, 기본 원리는 조건부 확률을 이용해 다음 단어를 예측하는 것이다.
1. 방대한 데이터에서 단어들의 출현 확률을 학습하고,
2. 문맥이 주어졌을 때 다음 단어의 확률을 계산하며,
3. 온도 등의 조절을 통해 창의적이고 자연스러운 문장을 생성한다.
이러한 방식으로 우리는 자연스럽고 유창한 AI 텍스트 생성기를 사용할 수 있게 되었다.
앞으로 AI가 더 발전하면서 언어 모델은 더 정교하고 인간다운 글을 생성할 것이다. 하지만 그 기본 원리는 여전히 확률을 기반으로 한 예측이라는 점을 기억해 두자.
이제 당신도 LLM의 마법이 어떻게 작동하는지 이해했을 것이다.
'엔지니어' 카테고리의 다른 글
| AI 로 소프트웨어 엔지니어링 팀 전체 레이오프 (0) | 2025.04.02 |
|---|---|
| 인공지능의 진화: 미래를 향한 기술의 로드맵 (0) | 2025.03.29 |
| 디지털 세상의 소통 방식: 네트워크 프로토콜 가장 많이 쓰이는 8가지 (0) | 2025.03.26 |
| 코드의 미래: AI와 인간 개발자의 공존과 경쟁 (0) | 2025.03.25 |
| Regression 이란? (2680) | 2023.03.22 |