결론부터말하면
Containerd 1.4.4-1의 rc 1.0.0-rc93의 문제로
이 버전만 피해가면 이슈 없음
상황
kubespray 2.16.0을 이용해서 k8s upgrade를 1.18 -> 1.19 수행하여 클러스터 업그레이드 완료.
이후 Pod의 상태를 확인하면서 CrashLoopBackOff, Error인 것들을 재시작 수행.
이 과정에 갑자기 Node가 NotReady가 되면서 그 node의 pod 전체가 다 Terminating 됨.
- 이때부터 pod 상태가 엉망이 됨.
노드의 상태가 NotReady였다가 일부 pod가 종료 처리되고 잠시 Ready 되었었다.
처음에는 pod에 짧은 시간에 많은 노드가 기동해서 그런가 싶었다.
문제파악
우선은 k8s의 노드의 kubelet 상태를 확인하였다.
kubelet은 k8s의 모든 노드에서 실행되는 Agent로써 이 서비스가 내려가면 노드가 동작하지 않는다.
간단하게 현재상태의 일부는 systemctl로도 조회 가능하다.
$ systemctl status kubelet
...
kubelet[3694]: I0220 14:23:09.120100 3694 kubelet.go:1775] skipping pod synchronization - [PLEG is not healthy: pleg was last seen active 4h19m47.369998188s ago; threshold is 3m0s]일단은 뭔가 pod가 갑자기 많이 기동하니까 동기화가 되지 않는 이슈로 생각했다.
좀더 자세히 보기 위해서 journalctl에 follow 옵션 줘서 실시간 발생하는 로그를 확인했다.
$ sudo journalctl -f문제있는 worker 노드에서 kubelet, containerd, docker를 재시작해서 노드를 Ready로 바꿔주고 다시 확인했다.
처음에는 pod들이 잘 뜨는것 처럼 보이다가
`PLEG is not healthy` 메시지가 보이는 순간
노드는 NotReady로 상태가 변경되면서 모든 pod가 다 Terminating 되었다.
PLEG (Pod Lifecycle Event Generator)
- Kubelet과 통신하여 노드에 떠있는 컨테이너 상태를 Pod 상태와 주기적으로 동기화.
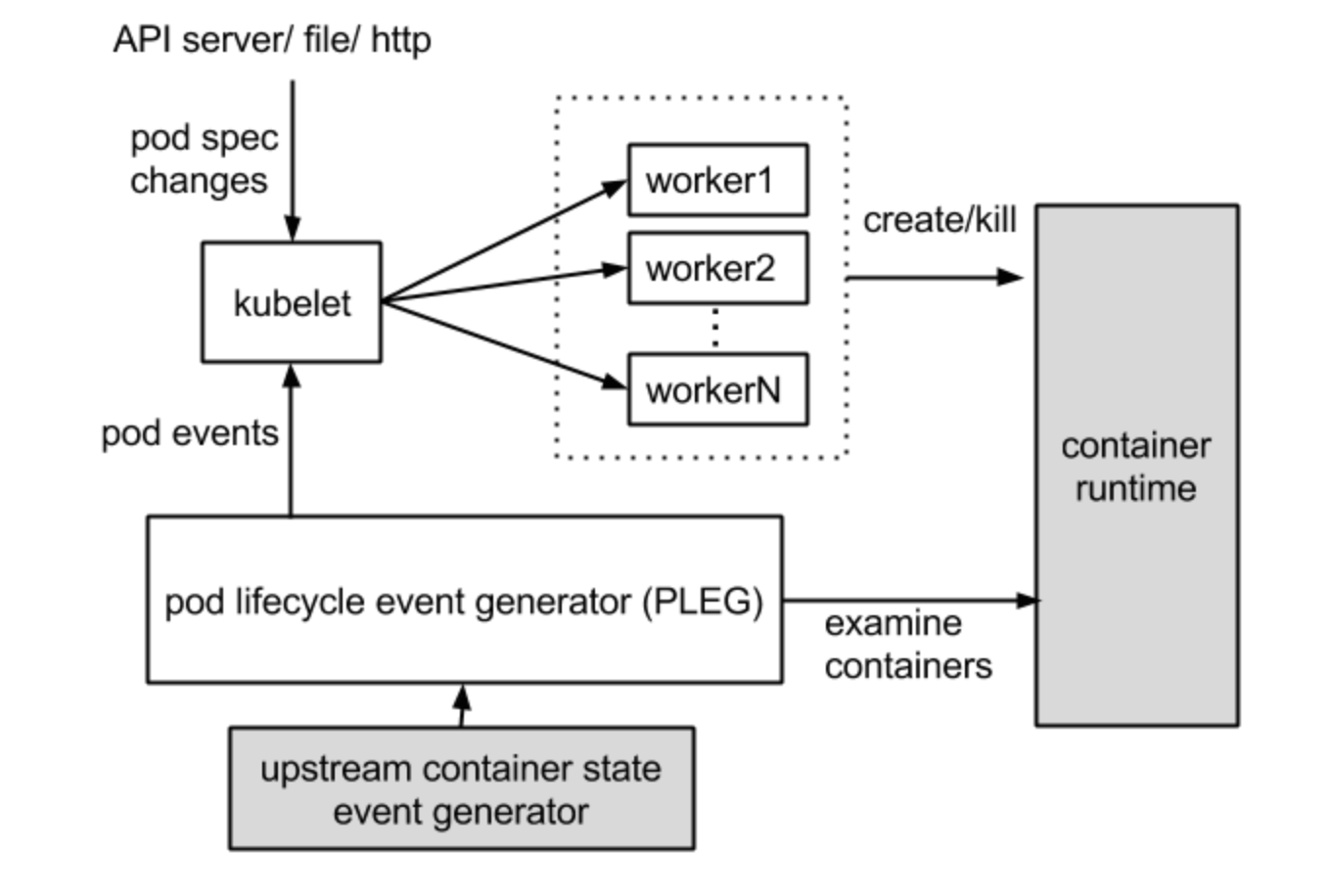
- Kubelet은 Control Plane에서 만든 spec에 맞춰 상태를 유지시키기 위해 각 pod의 상태 정보를 가지고 있어야 한다.
이런 상태 정보를 유지하기 위해 kubelet이 pod을 polling 하는 작업을 한다. 주기적으로 polling하는 작업은 pod의 수 가 증가함에 따라 무시할 수 없는 오버헤드가 발생한다.
Pod를 주기적으로 polling 하는 작업의 오버헤드를 줄이기 위해 PLEG (Pod Lifecycle Event Generator)를 사용한다
PLEG를 활용하는 것은 kubelet이 polling해서 정보를 가져오는 작업과 유사하지만 PLEG를 수행하는 싱글 쓰레드를 통해 컨테이너의 상태를 확인하여 kubelet이 polling하는 작업보다 오버헤드를 줄이는 효과를 볼 수 있다 - PLEG는 컨테이너 이벤트를 검색하기 위해 relist를 한다.
relist 하는 주기가 길다는 것은 kubelet이 컨테이너 변경 사항을 감지하고 파드 상태를 업데이트하는 데 시간이 더 오래 걸린다는 것을 의미한다. 반면에 주기가 짧으면 재등록(예: 컨테이너 런타임 작업)이 더 자주 발생하여 CPU 사용량이 증가하게 된다. 주기를 1초로 설정하더라도 컨테이너 런타임이 느리게 응답하거나 한 주기에 많은 컨테이너 변경 사항이 있는 경우 relisting 자체가 완료되는 데 1초 이상 걸릴 수 있다는 점에 유의한다.
대응
생각해보니 k8s 클러스터에 존재하는 pod 수가 적은 환경에서는 이슈가 없었는데
relist 하는 taint를
kubectl taint nodes worker-1 plegnothealthy=true:NoSchedule